#vector-search
2 articles
-
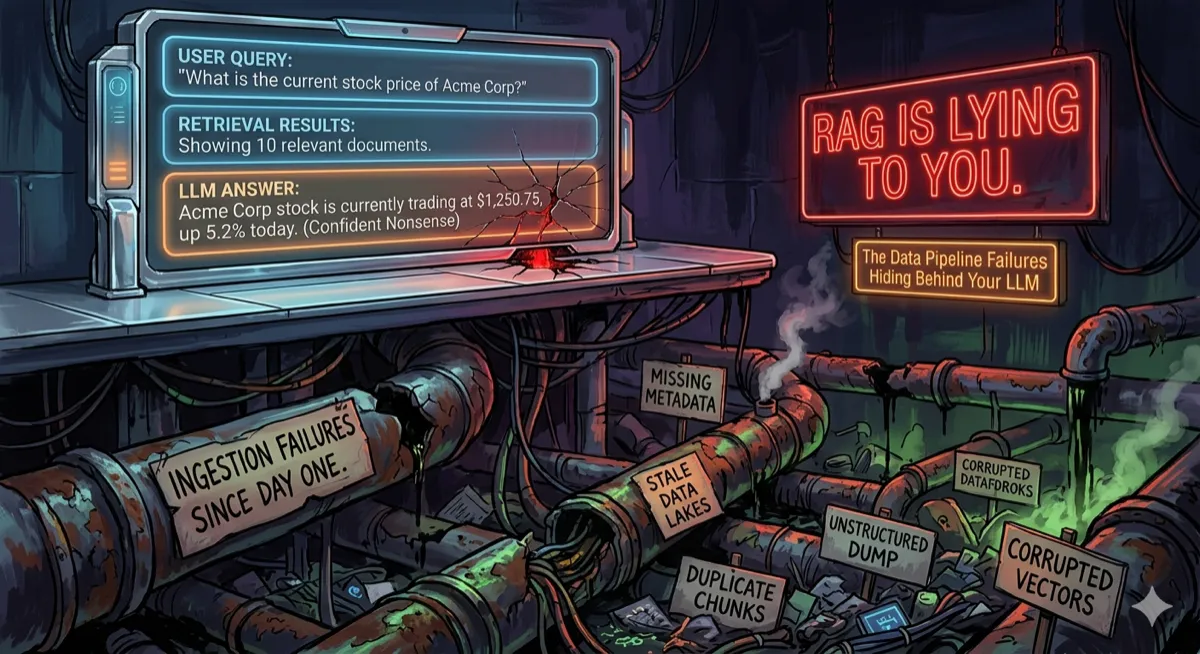
RAG Is Lying to You: The Data Pipeline Failures Hiding Behind Your LLM
80% of RAG failures trace to chunking decisions. Your retrieval returns results, your LLM generates answers, and your users get confident nonsense.
-

Your AI Is Drowning in Its Own Memory — Google Just Threw It a Lifeline
Shrink your LLM's memory footprint by 6x, speed up attention by 8x, and lose almost nothing in accuracy — no retraining required.