#llm
8 articles
-

The Gemma 4 Local Setup Guide Nobody Wrote Yet
Hardware-specific guide to running Gemma 4 locally: which model fits your Mac/GPU, Ollama vs MLX, Apple Silicon memory tuning, real tok/s numbers, and troubleshooting the things that actually break.
-

AutoAgent: The AI That Engineers Its Own Harness and Tops Benchmarks
AutoAgent autonomously builds and optimizes agent harnesses without human engineering, achieving #1 on SpreadsheetBench (96.5%) and top GPT-5 score on TerminalBench (55.1%) in 24-hour runs.
-

Gemma 4: The Pocket Rocket That Wants to Kill Your API Bill
Google DeepMind's Gemma 4 brings frontier-level reasoning to local hardware under Apache 2.0: 89.2% AIME, 80% LiveCodeBench, runs on phones to Mac minis, with native function calling and 256K context.
-
Karpathy Stopped Using LLMs to Write Code — He's Using Them to Think
Andrej Karpathy's LLM-powered personal knowledge base workflow: how he uses AI to compile, maintain, and query a 400K-word research wiki without vector databases or RAG.
-
Build a RAG System Without Embeddings or Vector Databases
PageIndex turns documents into navigable trees. An LLM reasons through the hierarchy to find answers — no embeddings, no similarity search, just structured retrieval.
-

An AI Agent Made $19,915 in 8 Hours. The Benchmark That Proved It Is Open Source.
ClawWork dropped 220 professional tasks across 44 job categories, gave AI agents $10 each, and told them to survive. One agent turned that into nearly twenty grand.
-
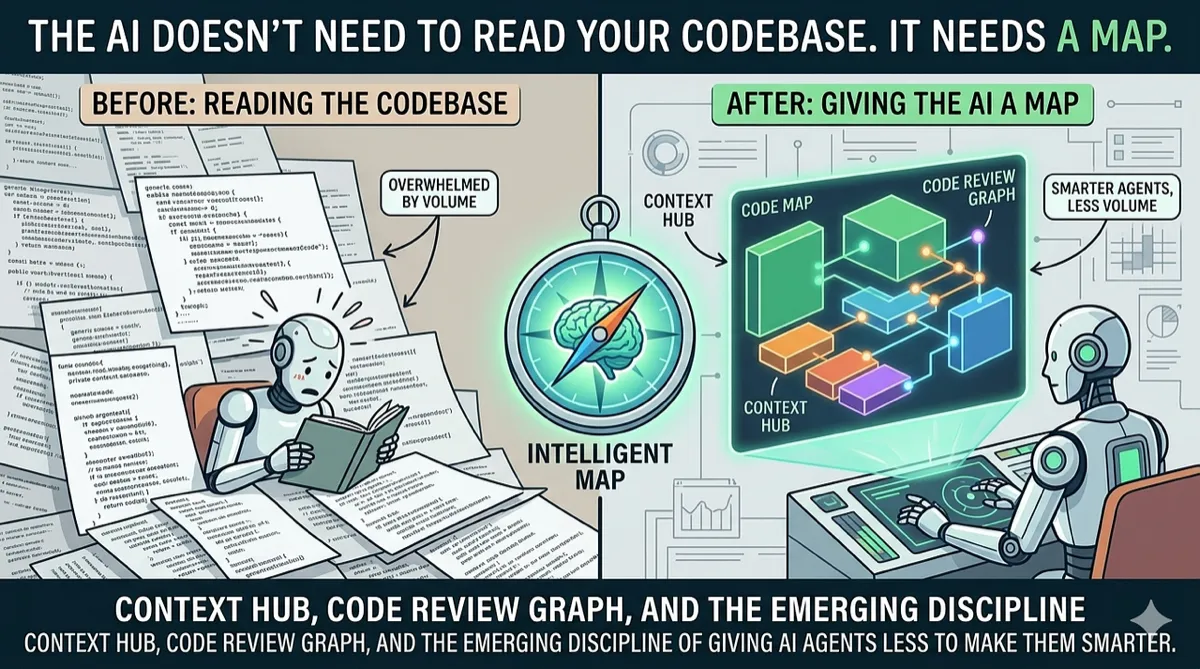
The AI Doesn't Need to Read Your Codebase. It Needs a Map.
Context Hub, Code Review Graph, and the emerging discipline of giving AI agents less to make them smarter.
-
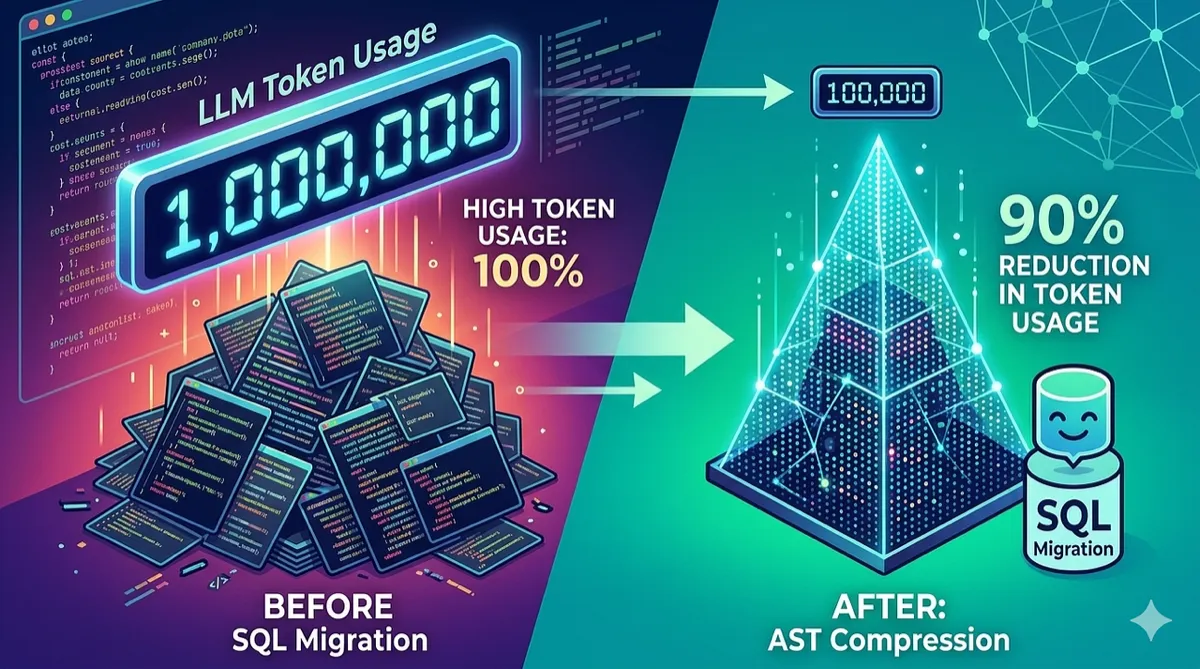
How We Cut LLM Token Usage by 90% in SQL Migration Using AST Compression
Feeding 200K-character SQL files to an LLM is expensive and unreliable. We built TOON — a compact AST notation that gives the model structural awareness at a fraction of the token cost.